LLM Coding Tools vs Traditional Development: A 2026 Workflow That Ships
AI writes fast. You still own the diff. Here is when to reach for LLM coding tools, when to type it yourself, and the quality gates that keep merges safe.
~17 min read
Last month an LLM "fixed" a race condition by adding a mutex to the wrong layer. The tests were green. Staging was not.
That is the whole debate in one incident. LLM coding tools are incredible accelerators for the boring 60% of software work. They are also confident about the dangerous 5%. Traditional development did not get obsolete. The winning teams in 2026 run a hybrid workflow with explicit gates, not a vibe merge.
I am a BCA student in Jaipur shipping Study Stream Black and client MERN work. I use Copilot and Cursor daily. I also debug production issues at midnight when nobody cares which tool drafted the code. This guide is what I wish someone handed me before I trusted a green CI badge on an AI-generated payment handler.
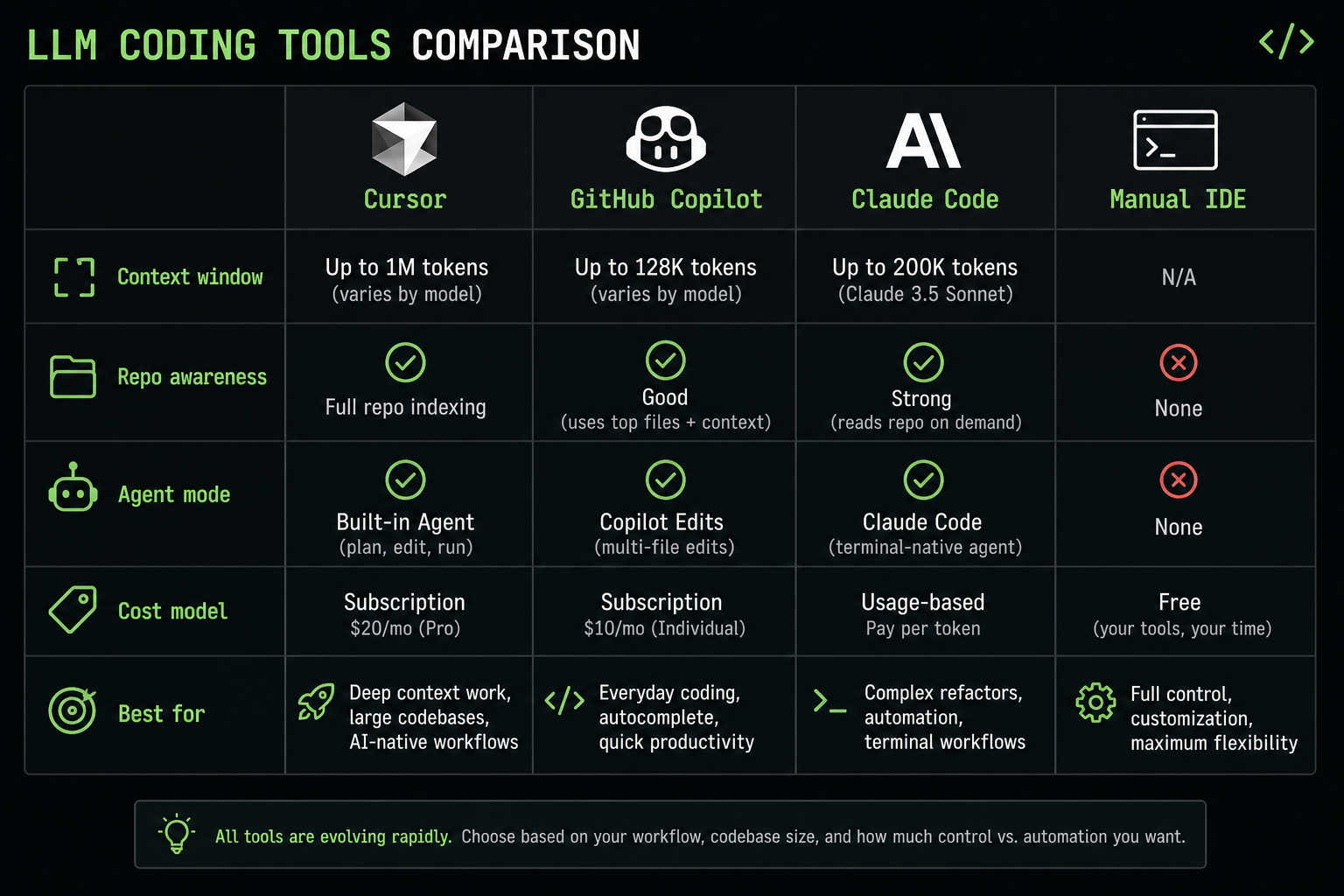
What counts as an LLM coding tool in 2026?
LLM coding tools are products where a language model participates in the edit loop: inline completion, chat in the IDE, agentic multi-file edits, or CLI agents that run tests and open PRs.
| Tool class | Examples | What it optimizes |
|---|---|---|
| Inline completion | GitHub Copilot, Cody inline | Keystrokes, boilerplate |
| IDE agent | Cursor, Windsurf | Repo-wide refactors, feature scaffolding |
| CLI / cloud agent | Claude Code, Codex-style runners | Autonomous loops with shell access |
| Traditional | Your editor + you | Judgment, novel design, audits |
The comparison is not "AI vs human." It is which step of the loop should be model-assisted.
Traditional development means you own the full loop: read the ticket, design the change, type the code, write the tests, run CI, respond to review, ship, and answer the pager. LLM tools compress the typing and search steps. They do not compress accountability.
Where LLM coding tools genuinely help
Models are strong when the task has high pattern density and low hidden state:
- Boilerplate — CRUD handlers, DTOs, form schemas, test scaffolds
- Mechanical refactors — rename across files, extract component, add types to untyped JS
- Explaining unfamiliar code — "what calls this function?" with repo context
- Regex, SQL, config drafts — first pass you verify
- Test ideas — table-driven cases you still assert manually
On a typical feature branch I use LLMs for the first draft of glue code and keep architecture decisions in my head (or in a short design note).
Example: scaffolding a typed API route
This is the kind of task I happily delegate. The patterns are well known. The risk is low if tests exist.
// app/api/notes/route.ts — after human review
import { z } from "zod";
import { NextResponse } from "next/server";
import { getSession } from "@/lib/auth";
import { db } from "@/lib/db";
const CreateNoteSchema = z.object({
title: z.string().min(1).max(120),
body: z.string().max(10_000).optional(),
});
export async function POST(request: Request) {
const session = await getSession(request);
if (!session) {
return NextResponse.json(
{ error: { code: "UNAUTHORIZED", message: "Sign in required" } },
{ status: 401 }
);
}
const parsed = CreateNoteSchema.safeParse(await request.json());
if (!parsed.success) {
return NextResponse.json(
{ error: { code: "VALIDATION", message: parsed.error.flatten() } },
{ status: 400 }
);
}
const note = await db.note.create({
data: { ...parsed.data, userId: session.userId },
});
return NextResponse.json({ data: note }, { status: 201 });
}
I might ask an agent to generate the Zod schema and handler skeleton from an OpenAPI snippet. I still rewrite error shapes to match our API contract and verify auth runs before any DB call. The model saved twenty minutes. It did not decide our error envelope.
Where LLMs still fail (and will burn you)
Models struggle when correctness depends on context you did not paste:
- Concurrency and distributed systems — subtle ordering, idempotency, exactly-once illusions
- Company tribal knowledge — "we never call that service synchronously on checkout"
- Security boundaries — authz checks, SSRF in webhooks, secrets in logs
- Performance without profiling — "add an index" guesses that miss composite keys
- Novel algorithms — they sound right; proofs are missing
If the bug costs money or safety when wrong, treat LLM output as untrusted input until a human who owns the system signs off.
The plausible-wrong failure mode
The scary bugs are not syntax errors. They are coherent wrong answers. On a client project the model suggested storing webhook idempotency keys in Redis with a 24-hour TTL. We already use Postgres with a unique constraint on event_id because finance needs an audit trail. Redis was faster on paper and wrong for our compliance story.
That is why I treat agent output like a junior dev's first PR: grateful for the speed, skeptical of the assumptions.
LLM-assisted vs traditional: decision matrix
| Situation | Prefer LLM assist | Prefer traditional |
|---|---|---|
| Greenfield CRUD in a known stack | Strong | — |
| Payments, auth, PII | Draft only | Own every line |
| Incident hotfix under pressure | Explain logs | Minimal diff you understand |
| Large refactor with tests | Agent + small PRs | — |
| Regulatory / audit trail | — | Documented manual process |
| Learning a new codebase | Q&A + navigation | — |
| Designing a new module's public API | Brainstorm only | You write the interface |
| Electron IPC or native bridges | — | Traditional + docs |
Traditional development still wins when the problem is coordination (teams, contracts, SLAs) more than typing. No model ships your cross-team migration plan.
For the org-design angle on who owns prompts vs systems, see prompt engineering vs software engineering. Different job, same repo.
The hybrid workflow that actually ships
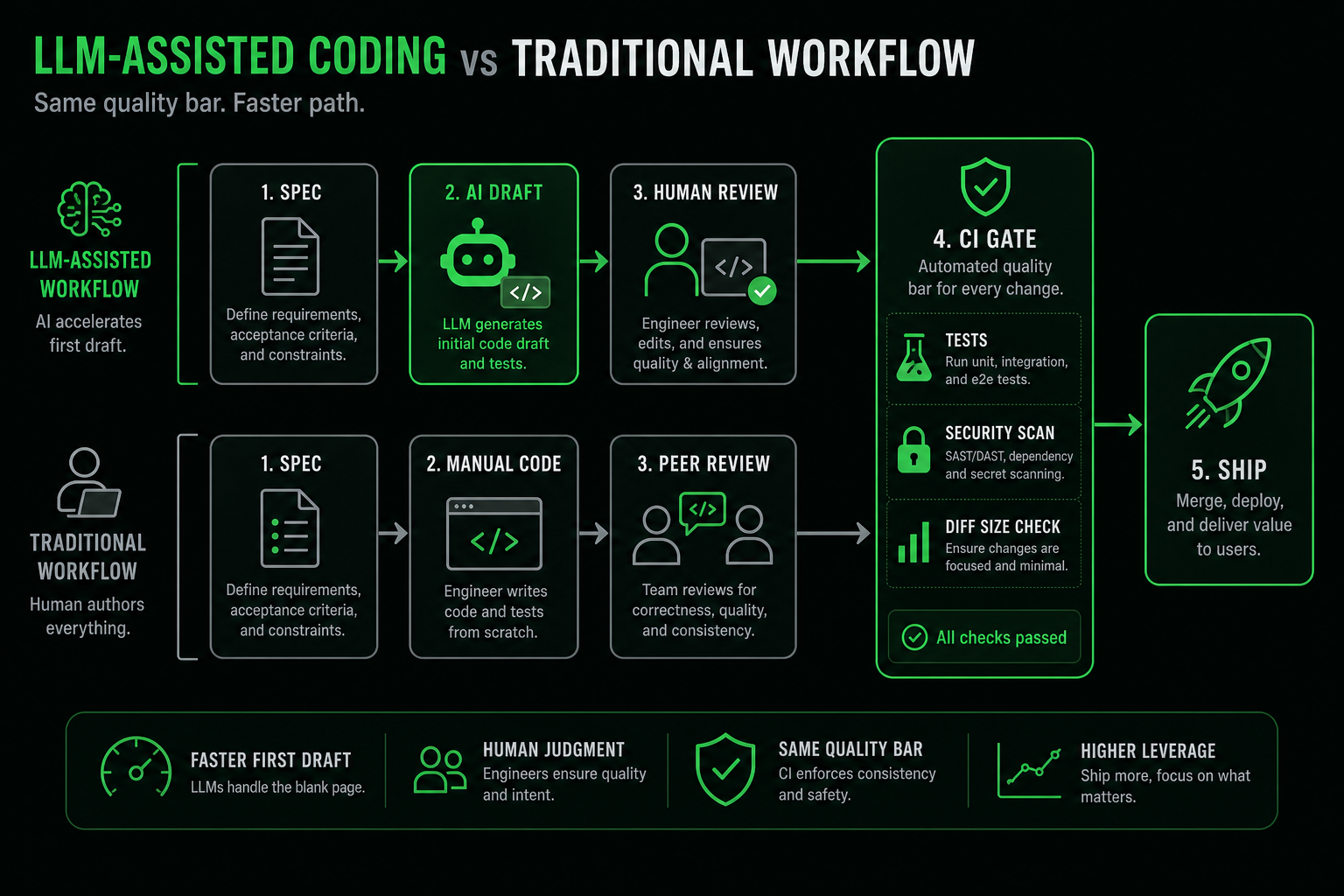
This is the loop I use on client work and Study Stream features:
- Spec — acceptance criteria in plain language (or a ticket template)
- Tests first — at least happy path + one failure case
- LLM draft — scoped prompt with file paths and constraints
- Human review — read the diff like a junior dev's PR
- CI — lint, unit, integration, security scan
- Ship — feature flag if the blast radius is wide
flowchart LR
SPEC[Spec + acceptance tests]
DRAFT[LLM draft scoped prompt]
REVIEW[Human review diff]
CI[CI: test lint scan]
SHIP[Ship behind flag]
SPEC --> DRAFT --> REVIEW --> CI --> SHIP
REVIEW -->|reject| DRAFT
CI -->|fail| DRAFT
The arrow back from review to draft is intentional. "Make it pass CI" without reading the failure is how you accumulate debt.

When to stay fully traditional for a task
I still type manually when:
- The change is under 30 lines and I already know the file
- I am debugging and need tight feedback loops in the debugger
- I am writing the contract other code will depend on (types, public hooks, DB schema)
- I am in an incident and need the smallest possible diff
Hybrid does not mean "AI for everything." It means defaulting to AI for drafts and defaulting to human judgment for boundaries.
Spec-first prompting (copy-paste pattern)
Vague prompts produce vague bugs. I use a fixed shape:
## Task
Add rate limiting to POST /api/notes
## Constraints
- Use existing Redis client in lib/redis.ts
- Max 60 req/min per user id
- Return 429 with Retry-After header
- Do not change auth middleware
## Files you may edit
- app/api/notes/route.ts
- lib/rate-limit.ts (create)
## Tests required
- allows under limit
- blocks over limit
- ignores unauthenticated (existing behavior)
The model spends tokens on code instead of guessing architecture.
Rate limit helper (what I verify after generation)
// lib/rate-limit.ts
import { redis } from "@/lib/redis";
const WINDOW_SEC = 60;
export async function consumeRateLimit(
key: string,
limit: number
): Promise<{ allowed: boolean; retryAfterSec?: number }> {
const bucket = `rl:${key}`;
const count = await redis.incr(bucket);
if (count === 1) {
await redis.expire(bucket, WINDOW_SEC);
}
if (count > limit) {
const ttl = await redis.ttl(bucket);
return { allowed: false, retryAfterSec: Math.max(ttl, 1) };
}
return { allowed: true };
}
I check three things the model often misses: atomicity (INCR + EXPIRE race), key namespace (no collisions across routes), and clock skew on Retry-After. The draft gets me 80% there. The last 20% is why we still employ engineers.
Quality gates: never merge naked AI output
Minimum bar before merge:
| Gate | What it catches |
|---|---|
| CI green | Regressions, type errors |
| Peer review on sensitive paths | auth, payments, crypto |
| Diff size sanity | 800-line drive-by refactors hiding injections |
| Secret scan | accidental .env keys in comments |
| Dependency diff review | surprise postinstall scripts |
| Coverage on touched files | happy-path-only AI tests |
Example GitHub Actions slice (adjust to your stack):
name: pr-quality
on: [pull_request]
jobs:
verify:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: "22"
cache: npm
- run: npm ci
- run: npm run lint
- run: npm test -- --coverage
- run: npm run build
- name: Block huge AI dumps
run: |
lines=$(git diff --stat origin/${{ github.base_ref }}... | tail -1 | awk '{print $4}')
if [ "${lines:-0}" -gt 500 ]; then
echo "Diff too large (${lines} lines). Split the PR."
exit 1
fi
The line-count gate is crude. It has stopped two bad merges this year.
PR review checklist for AI-assisted diffs
I paste this mentally (sometimes literally in review comments) when the PR author used an agent:
- Does every changed file belong to the ticket? Agents love drive-by "cleanup."
- Are new dependencies justified? Check
package-lock.jsondiff line by line. - Did tests assert behavior, not implementation? AI loves
toHaveBeenCalledWithon internals. - Any silent behavior change? Default values, error swallowing, widened CORS.
- Secrets or PII in logs? Models sprinkle
console.logfor debugging.
Good vs bad AI-generated tests
// Bad: tests the mock, not the product
it("calls createNote", async () => {
const spy = vi.spyOn(db.note, "create");
await POST(mockRequest({ title: "x" }));
expect(spy).toHaveBeenCalled();
});
// Good: asserts HTTP contract
it("returns 401 when session is missing", async () => {
const res = await POST(mockRequest({ title: "x" }, { session: null }));
expect(res.status).toBe(401);
const body = await res.json();
expect(body.error.code).toBe("UNAUTHORIZED");
});
I often ask the model for test ideas, then delete half of them. Generated suites look impressive in PR stats and miss the edge case that actually breaks in prod.
Tool-by-tool: Cursor vs Copilot vs CLI agents
GitHub Copilot
Best for: inline completion inside files you already understand.
Copilot shines when you are in flow state on familiar code. It predicts the next line of a React component, a Jest table case, or a Mongoose schema field. Context is local. Risk stays low because you are usually accepting small hunks.
I keep Copilot on for TypeScript and turn it off when writing security-sensitive parsers (JWT validation, webhook signature checks). Tab-complete is hypnotic. You stop reading.
Weak for: repo-wide refactors, "implement this ticket end to end," anything that needs more than one file of context.
Cursor (agent mode)
Best for: multi-file features when you provide paths, constraints, and tests.
Cursor is where I run scoped agent tasks: "add rate limiting per the spec, only edit these two files." I work on a branch, never on main. MCP in Cursor helps for structured repo search and GitHub operations, but I still read every tool call side effect. An agent with write access to your filesystem is a power tool, not a toy.
Weak for: open-ended "fix the app" prompts. That is how you get 14 changed files and a bumped dependency you did not notice.
| Scenario | Copilot | Cursor agent |
|---|---|---|
| Add field to existing form component | Strong | Overkill |
| Rename hook across 12 files | Weak | Strong |
| Explain unfamiliar module | Weak | Strong (with @ references) |
| One-line fix while debugging | Strong | Slow |
| Scaffold feature from ticket | Weak | Strong (with spec prompt) |
Claude Code / CLI agents
Best for: repetitive repo chores with clear stop conditions.
Rename imports after a package move. Add missing license headers. Generate CHANGELOG entries from commits. I cap runtime, require a clean git status before start, and a human publishes anything that leaves the machine.
CLI agents overlap with production AI agents: same loop, same need for step limits. The difference is the blast radius is your repo, not your customers' data. Still worth guarding.
Traditional IDE (no agent)
Still the right choice for designing a new module's public API, debugging heisenbugs, and writing the five lines that must be exactly right.
I reach for plain VS Code/Cursor manual mode when the problem is why not what. Stack traces, memory profiles, network waterfalls. No model shortcut replaces measuring.
A real week: where each mode won
Monday — LLM assist: Scaffolded a Next.js API route + Zod schema from an OpenAPI snippet. Saved ~45 minutes. I rewrote error handling to match our { error: { code, message } } shape.
Tuesday — Traditional: Tracked a memory leak in Electron. Needed DevTools, heap snapshots, and reading our IPC layer. No model shortcut. This is the same skill story as TypeScript + React shipping patterns: tools do not replace knowing the runtime.
Wednesday — LLM assist: Generated table-driven tests for a pure function. Kept two cases, deleted four overfitted ones the model invented.
Thursday — Traditional + review: Payment webhook idempotency. LLM suggested Redis TTL keys. We use Postgres with a unique constraint. Plausible and wrong for ops.
Friday — Hybrid: Agent refactored folder structure; I split the PR into "move only" then "logic change" so reviewers could follow it. Mechanical moves get agent help. Logic changes get human authorship.
Rough time split for me in 2026: 40% LLM-assisted drafts, 35% traditional writing/debugging, 25% review and CI triage. Your ratio will vary by domain. Infra-heavy teams may stay more traditional. CRUD-heavy products may skew higher on agents.
What we tried that did not work
"Agent, ship the feature end-to-end." Without step limits it touched unrelated files, bumped dependencies, and silenced a lint rule. We moved to scoped prompts and smaller PRs.
Skipping tests because "the AI wrote them." Generated tests often assert implementation details and miss edge cases. Tests are part of the spec, not a postscript.
Pasting prod errors with full PII into cloud chat. Policy violation and a retention problem. Redact, reproduce locally, then ask. Same discipline as developer breach controls: minimize what leaves your machine.
Letting the model pick the database migration strategy. It proposed dropping a column in one step. We needed expand-contract for zero-downtime deploys. Traditional migration design matters more when AI can execute fast.
Team policies worth writing down
If your team uses LLM coding tools ad hoc, you get silent inconsistency. These belong in CONTRIBUTING.md or an internal RFC:
- Sensitive paths (auth, billing, crypto) require human authorship or senior review, no exceptions
- Maximum agent PR size without split approval (we use 500 lines changed as a soft cap)
- No production credentials in prompts; use redacted logs and local repro
- Dependency changes need explicit callout in PR description
- Record agent use in PR template checkbox (not for shame, for audit and retros)
None of this is anti-AI. It is pro-predictable quality.
Architecture: where LLM tools sit in your stack
flowchart TB
subgraph dev [Developer]
YOU[Engineer]
end
subgraph ide [IDE Layer]
COP[Inline completion]
AG[Agent / Chat]
MCP[MCP tools read-only default]
end
subgraph repo [Repository]
CODE[Source + tests]
CI[CI pipeline]
end
YOU --> COP
YOU --> AG
AG --> MCP
AG --> CODE
YOU --> CODE
CODE --> CI
CI -->|pass| YOU
MCP belongs in the diagram because the best IDE agents in 2026 are only as safe as the tools you expose. Read-only Git and search by default; approve writes. If you are wiring tools, start with what MCP is before giving an agent shell access.
The model is not in your production runtime by default. It sits in the authoring path. Production still runs code you merged. That separation is a feature. Keep it.
When traditional development still wins outright
- Safety-critical systems (medical, aviation, certain fintech)
- Formal verification or compliance evidence requirements
- Greenfield architecture where the cost of the wrong abstraction is quarters, not hours
- Team alignment — whiteboards, RFCs, ADRs; models do not attend standup
- Performance work that needs profiling data, not suggestions
- Security reviews where exploit chains matter more than syntax
Career angle in 2026
Typing speed matters less. Judgment, ownership, and debugging matter more. The developers who thrive treat LLMs like a fast intern: great output when supervised, liability when not.
For hiring and leveling, see AI replacing developers?. For agents touching your repo autonomously, see the AI agents landscape. For shipping real apps with modern React, see MERN patterns in production.
If you are a student, the bar moved: you need fewer tutorial repos and more evidence you review code critically, including your own AI drafts.
FAQ
Is GitHub Copilot enough, or do I need Cursor?
Copilot is enough if you mostly want completions inside files you already understand. Cursor (or similar agents) helps when you routinely need multi-file edits with repo context. Many developers use both. Pick based on workflow, not Twitter polls.
Does AI-generated code belong in production?
Yes, after the same gates as human code: review, tests, CI, security scan. "AI wrote it" is not a quality attribute. Ownership stays with the engineer who merges.
How big should an AI-assisted PR be?
Small enough that a reviewer can understand it in one sitting. Under 300–500 changed lines is a reasonable team norm unless the PR is mechanical moves only. Larger diffs need split PRs or traditional manual execution.
Will LLM coding tools replace junior developers?
They replace some tasks juniors used to do (scaffolding, simple fixes). They do not replace the learning that comes from owning incidents, reading production metrics, and designing systems. Teams still need juniors; they need clearer mentorship and stronger review culture.
Should I let the agent run terminal commands?
Only with boundaries: allowlisted commands, sandboxed env, no production credentials, and a human reading the output. An agent that can npm install and git push can also curl | bash if you are careless. Treat shell access like production deploy access.
How is this different from vibe coding?
Vibe coding skips spec, review, and gates. Hybrid workflow uses the model for speed but keeps the same quality bar as traditional development. The CI gate does not care who typed the characters.
Read next
- AI agents landscape 2026
- Prompt engineering vs software engineering
- TypeScript + React shipping patterns
- MCP for developers
- How to use MCP in Cursor
Pick one feature this week. Write the spec and tests, let the model draft, then review like it was written by someone who does not pay for the outage. That is the whole comparison in practice.
Written by Rohit Singh, software developer in Jaipur. I build Study Stream Black and write about shipping real code on the blog.